RPC与HTTP
RPC与HTTP区别
RPC(Remote Procedure Call)远程过程调用协议,一种通过网络从远程计算机上请求服务,而不需要了解底层网络技术的协议
宏观区别
HTTP 是应用层协议
RPC 是远程调用过程,它是调用方式,对应的是本地调用
所谓 RPC 协议,实际上是基于 TCP、UDP、甚至 HTTP2 改造后的自定义协议
https://www.github-zh.com/projects/693342566-system-design-101#how-does-grpc-work

编解码层区别
网络传输前,需要结构体转换为二进制数据 -> 序列化
HTTP/1.1
- 序列化协议:JSON
- 额外空间开销大,没有类型,开发时需要通过反射统一解决

RPC
序列化协议:以 gRPC 为代表的 Protobuf,其他也类似
序列化后的体积比 JSON 小 => 传输效率高
序列化、反序列化速度快,开发时不需要通过反射 => 性能消耗低
IDL 描述语义比较清晰
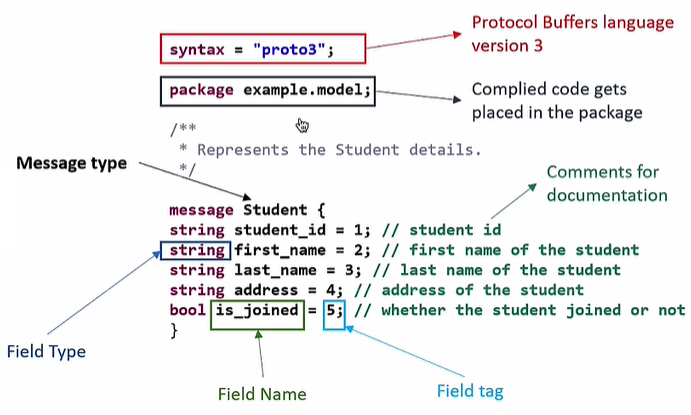
协议层区别
基于 TCP 传输,都会有消息头和消息体,区别在于消息头
HTTP/1.1
- 优点是灵活,可以自定义很多字段
- 缺点是包含许多为了适应浏览器的冗余字段,这是内部服务用不到的
RPC
- 可定制化,自定义必要字段即可
- 可摒弃很多 HTTP Header 中的字段,比如各种浏览器行为
网络传输层区别
本质都是基于 Socket 通信
HTTP/1.1
- 建立一个 TCP 长连接,设置 keep-alive 长时间复用这个连接
- 框架中会引用成熟的网络库,给 HTTP 加连接池,保证不只有一个 TCP 连接可用
RPC
- 建立 TCP 连接池,框架也会引入成熟网络库来提高传输性能
- gRPC 基于 HTTP/2,拥有多路复用、优先级控制、头部压缩等优势
RPC框架
RPC优势和不足
优势
- 相较于 HTTP/1.1,数据包更小、序列化更快,所以传输效率很高
- 基于 TCP 或 HTTP/2 的自定义 RPC 协议,网络传输性能比 HTTP/1.1 更快
- 适用于微服务架构,微服务集群下,每个微服务职责单一,有利于多团队的分工协作
不足
- RPC 协议本身无法解决微服务集群的问题,例如:服务发现、服务治理等,需要工具来保障服务的稳定性
- 调用方服务端的 RPC 接口有强依赖关系,需要有自动化工具、版本管理工具来保证代码级别的强依赖关系。例如,stub 桩文件需要频繁更新,否则接口调用方式可能出错
使用场景
- 微服务架构下,多个内部服务器调用频繁,适用于 RPC
- 对外服务、单体服务、为前端提供的服务,适用于 HTTP。特别是 HTTP/2 性能也很好
RPC框架对比
编解码层
目标
- 生成代码:生成代码将 IDL 文件转换成不同语言可以依赖的 lib 代码(类似于库函数)
- 序列化 & 反序列化:对象 <-> 二进制字节流
选型
- 安全性
- 通用性:跨语言、跨平台
- 兼容性:序列化协议升级后,保证原服务的稳定性
- 性能
- 时间:序列化反序列化的速度
- 空间:序列化后的数据体积大小,体积越小,网络传输耗时越短
协议层
目标
- 支持解析多种,包括:HTTP、HTTP2、自定义 RPC 协议、私有协议等
RPC 通信协议的设计
大厂内部大部分用自定义的 RPC 协议,灵活+安全
- 作用:TCP 通道中的二进制数据包,会被拆分、合并,需要应用层协议确定消息的边界(说人话:得知道哪几个二进制包是这一条请求)
- 协议构成
- 协议头-固定部分:整体长度、协议头长度、消息类型、序列化方式、消息 ID 等
- 协议头-扩展部分:不固定的扩展字段,各种协议 DIY 的字段
- 协议体:业务数据
网络传输层
一般使用成熟的网络通信框架(例如:Netty),会和 RPC 框架解耦
目标
- IO 多路复用实现高并发、可靠传输
选型指标
- 易用:封装原生 socket API
- 性能:零拷贝、建立连接池、减少 GC 等
RPC热门框架
跨语言调用型
典型代表:grpc、thrift 特点:
- 提供最基础的 RPC 通信能力
- 专注于跨语言调用,适合不同语言提供服务的场景
- 没有服务治理等相关机制,需要借助其他开源工具去实现服务发现、负载均衡、熔断限流等功能
服务治理型
典型代表:rpcx,kitex,dubbo 特点:
- 提供最基础的 RPC 通信能力
- 服务定义(函数映射)
- 多消息传输协议(序列化协议)
- 多网络通信协议(TCP、UDP、HTTP/2、QUIC等)
- 提供服务治理能力:服务发现、负载均衡、熔断限流等
服务注册
服务发现
定位:服务名 -> 服务地址(服务节点)
- 在 RPC 框架下发起 RPC 调用时,就像调用本地方法一样,意味着,Client 代码里写的是 Server 的服务名和方法名
- 需要一个机制,让 Client 根据服务名,查询到 Server 的 IP 和端口
- DNS:域名 → IP 可以满足,但是不能使用 DNS,原因如下:
- DNS 多级缓存机制,导致 Client 不能及时感知到 Server 节点的变化
- DNS 不能注册端口,所以只能用来注册 HTTP 服务

服务上线
Server启动后,向 Registry注册自身信息查
Registry 保存着所有服务的节点信息
Server 与 Registry 保持心跳,Registry 需要感知 Server 是否可用
Client 第一次发起 RPC 调用前,向 Registry 请求服务节点列表,并把这个列表缓存在本地
- Client 与 Registry 保持数据同步,服务节点有变化时,Registry 通知 Client,Client 更新本地缓存
Client 发起 RPC 请求,Server 返回响应
服务下线
- Server 通知 Registry 当前节点(A)即将下线
- Registry 通知 Client,Server 的A节点下线
- Client 收到通知后,更新本地缓存的节点列表,选择 Server 的其他节点发请求
- Server 等待一段时间后(防止网络延迟,有一些存量请求需要处理),暂停服务并下线
CAP

含义
- C:一致性,所有节点同时看到的数据相同
- A:可用性,任何时候都能被读写,至少有一个服务节点可用
- P:分区容错性,部分节点出现网络故障时,整个系统对外还是能正常提供服务
在分布式系统中,由于节点之间的网络通信会存在故障,可能存在服务节点的宕机,所以 P 是必须项
- 在保证P的前提下,CA 难以同时满足,只能说在 CP 下尽量保证 A,在 AP 下尽量保证 C
CP or AP
- CP:牺牲一定的可用性,保证强一致性,典型代表有 ZooKeeper、etcd
- AP:牺牲一定的一致性,保证高可用性,典型代表有 Eureka、Nacos
- 选型:
- 体量小,集群规模不大的时候,CP 可以满足需要
- 体量大,有大批量服务节点需要同时上下线,选择 AP
- 注册中心可能会负载过高:有大量的节点变更的请求、服务节点列表下发不及时
- 强一致性,就需要同步大量节点之间的数据,服务可能长时间不可用
心跳机制
如何识别服务节点是否可用:心跳机制
目的:Client 实时感知 Server 节点变化,避免给不可用节点发请求
正常流程
- Server 每隔几秒向 Registry 发送心跳包,收到响应则表示服务节点正常,在指定时间内没收到响应,则判定为失败
- 注册中心发现某个节点不可用时,会通知 Client,Client 更新本地缓存的服务节点列表
特殊情况
心跳断了不代表服务宕机,也许是网络抖动(TCP 可能有问题),不能判断出服务节点不可用
- 发现心跳断了,Registry 立即通知 Client 某节点不可用,避免服务真的宕机时,仍然有请求发来
- Registry 继续向 Server 发心跳,如果发几次心跳都是失败的,才认为服务节点不可用。如果心跳恢复,再告知 Client 服务节点可用
- 重试策略:先连续发几次心跳,过一定时间间隔后再发心跳,需要考虑重试次数和重试间隔
负载均衡
负载均衡在解决什么问题
为了保证服务的可用性,一个应用会部署到多个节点上,这些节点构成服务集群,这也是分布式架构/微服务架构的显著特点之一
如何把请求分发给集群下的每个节点,是负载均衡要解决的问题。这里的分发至少包含2个方面:
- 请求尽量均匀地打在各个节点上,每个节点都能接收请求
- 提高请求的性能,哪个节点响应最快,就优先调用哪个节点
有哪些负载均衡算法
随机、加权随机
- 通过随机算法,生成随机数,节点足够多、访问量足够大时,每个节点被访问的概率基本相同
- 适用场景:请求量大,各个节点的性能差异不大
轮询、加权轮询
- 按照固定顺序,挨个访问可用的服务节点
- 给节点赋权重,权重越大,被访问的概率越高
- 如何调整节点的权重?成功+ 失败-
- 场景:存在新老机器,节点性能不同,发挥新节点的优势
哈希、一致性哈希
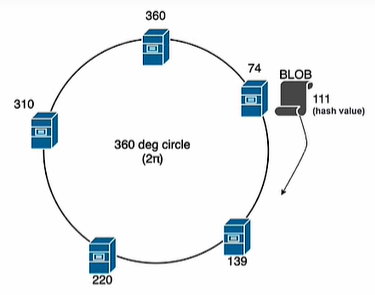
- 通过哈希函数把服务节点放到哈希环上
- 与 本地缓存 相结合,同一来源的请求计算出的哈希值相同,同一来源的请求都映射到同一节点,提高缓存的命中率
- 场景:不同客户端请求差异大,需要用到本地缓存
指标类
- 最少连接法
- 用 Client - Server 间的连接数代表节点的负载
- 场景:节点性能差异大,但不好提前做好权重定义
- 最少活跃数
- 用活跃请求数(已经接收但没有返回的请求),代表负载
- 缺陷:每个请求耗时不同,请求数不能代表实际负载
- 最快响应时间
- 指标:平均耗时、TP99、TP999,选响应时间最短的
- 最少连接法
熔断限流降级
熔断
场景
服务端出现问题
- 服务指标:响应时间、错误率、连续错误数等,设置一个值,持续超过值触发熔断
- 硬件指标:CPU、内存、网络 IO
目的
- 服务端恢复需要时间,服务端需要歇一歇
- 避免全调用链路崩溃,不能把请求再发给 Server 了,一堆积带来其他服务也出问题

熔断器直接抛出熔断的异常响应,三个状态切换,决定是否处于熔断状态
流程
- Server 被监控到异常,触发熔断,熔断器抛出熔断的异常响应
- Client 收到异常,利用负载均衡重新选择节点,后续请求不再打到被熔断的节点
- 一段时间后,Cient 再对这个节点重新请求,如果正常响应,则缓慢对这个节点放开流量,如果仍然是熔断,则继续执行 Step 2,如此循环
限流
场景 & 目标
- 突发的流量增大,使系统崩溃。
- 判断指标:节点当前连接数、QPS 等
手段
静态算法
令牌桶:系统以恒定速率产生令牌并把令牌放到桶里,每个请求从桶里拿到令牌才会被执行,反之被限流

漏桶:令牌桶的特殊情况,令牌桶的桶容量为 0 就是漏桶。系统匀速产生令牌,没被取走也不会积攒下来。系统处理请求是均匀的
对比:令牌桶允许积攒令牌,可以解决偶发的流量突变。令牌桶的容量不能设置太大,否则达不到限流效果

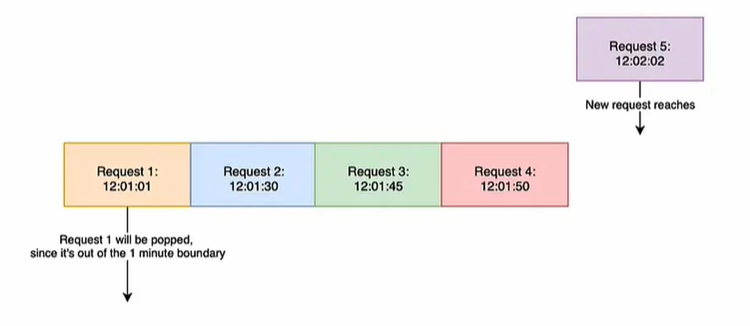
固定窗口:固定时间段内,只执行固定数量的请求

滑动窗口:类似于固定窗口,只是滑动窗口会随着时间线挪动窗口
- 窗口时间以秒为单位更合适,用分钟为单位时,不能保证分钟内的请求是均匀分布的,还是 0 会有系统崩溃的可能
动态算法:BBR
- 类似于 TCP 的拥塞控制,根据一系列指标来判定是否需要触发限流
流程
- 在中间件记录流量和阀值,并在中间件中实现限流算法
- 对于偶发性的触发限流,只要在超时范围内,可以同步阻塞等待请求被处理
- Server 的某个节点触发了非偶发性限流,Client 利用负载均衡调低该节点的权重,尽量少向这个节点发请求
- 区别于熔断的不再发请求,限流仍然会发请求,只是降低频率
降级
场景 & 目的
- 系统出现故障后的补救措施,或可预见的故障前的应对措施,来保证整体的可用性
手段
- 考虑停用部分监控埋点、日志上报等观测类中间件
- 根据业务场景判断,停用边缘服务,返回服务繁忙之类的响应
- 对于有缓存的接口,降级时只查缓存,不查 DB,没命中缓存则返回错误的响应
核心思想
- 如何判断节点的健康状态?是否需要熔断/限流/降级?
- 通过监控看指标:QPS、连接数、节点负载等
- 熔断/限流/降级后,怎么恢复?
- 熔断限流搭配负载均衡,等节点恢复正常后,再重新选择
- 降级有时是手动恢复
超时重试幂等
超时
应用场景
- 只要涉及网络调用、服务器宕机等问题,就需要设置超时和重试,例如:微服务内部的调用、对数据库、缓存、MQ、第三方接口、中间件等的调用
基本概念
- 当请求超过设置时间还没被处理,则直接被取消,抛出超时异常
- 目的是,尽量不在服务端堆积请求连接,既会影响新请求的处理,也可能导致系统崩溃
实现细节:设置超时时间
- 根据响应时间调整:TP99(或TP999)都在 x 时间范围内,那么超时时间可以设置为 99 线
- 接入可观测工具,加监控,确定 TP99
- 做压力测试,确定 TP99
大厂实践:只要与第三方打交道,针对不同的调用下游(数据库、Redis、Kafka、第三方接口等),都设置不同的超时时间
重试
基本概念
- 调用第三方接口时,搭配超时来用,多次发送相同的请求,避免网络抖动和偶然故障
- 目的是,尽可能让请求被成功处理。由于偶然故障发生频率小,重试对服务器的资源消耗可以忽略不计
实现细节:设置重试次数
- 设置重试次数、重试间隔。重试次数不宜过多,否则会给系统负载带来压力,造成系统雪崩
幂等
f(x)=f(f(x)),例如求绝对值的函数
核心思想
- 保证同一个请求不被多次执行
发生场景
- 请求的响应结果是超时,并不能确定是服务端没处理(前方请求堆积,排不上队),还是服务端处理了发送响应时,碰到了网络抖动导致超时
重试困境
- 执行重试,可能会出现请求多次执行的情况
- 不重试,可能出现请求一次都没被执行的情况
设计幂等接口:幂等去重
非幂等操作 → 幂等操作
针对写请求的接口,对请求进行去重,确保同一个请求处理一次和多次的结果是相同的,即幂等接口
去重逻辑:
- 请求方每次请求生成唯一的 ID,在首次调用和重试时,唯一的ID 保持不变
- 服务端收到请求时,查询 ID 是否被处理过,处理过则直接返回结果,不再重复执行业务逻辑