操作系统
线程崩溃,进程也会崩溃吗?
一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃。为什么系统要让进程崩溃呢?
- 主要是因为进程中,各个线程地址空间是共享的。既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
线程崩溃后,进程是如何崩溃的呢?
- 答案是信号
- 比如:想要干掉一个正在运行的进程经常用
kill -9 pid。kill 其实就是给指定 pid 发送终止信号,其中的 9 就是信号

发个信号进程就崩溃了,这背后的原理是怎样的
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑会让进程退出
注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
int main(void) {
// 忽略信号
signal(SIGSEGV, SIG_IGN);
// 产生一个 SIGSEGV 信号
raise(SIGSEGV);
printf("正常结束");
}如何让正在运行的 Java 工程优雅停机?
- JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出
- 这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清除了
为什么线程崩溃不会导致 JVM 进程崩溃?
- 因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃
JVM_handle_linux_signal(int sig,
siginfo_t* info,
void* ucVoid,
int abort_if_unrecognized) {
// Must do this before SignalHandlerMark, if crash protection installed we will longjmp away
// 这段代码里会调用 siglongjmp,主要做线程恢复之用
os::ThreadCrashProtection::check_crash_protection(sig, t);
if (info != NULL && uc != NULL && thread != NULL) {
pc = (address) os::Linux::ucontext_get_pc(uc);
// Handle ALL stack overflow variations here
if (sig == SIGSEGV) {
// Si_addr may not be valid due to a bug in the linux-ppc64 kernel (see
// comment below). Use get_stack_bang_address instead of si_addr.
address addr = ((NativeInstruction*)pc)->get_stack_bang_address(uc);
// 判断是否栈溢出了
if (addr < thread->stack_base() &&
addr >= thread->stack_base() - thread->stack_size()) {
if (thread->thread_state() == _thread_in_Java) { // 针对栈溢出 JVM 的内部处理
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
}
}
}
}
if (sig == SIGSEGV &&
!MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)) {
// 此处会做空指针检查
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
}
// 如果是栈溢出或者空指针最终会返回 true,不会走最后的 report_and_die,所以 JVM 不会退出
if (stub != NULL) {
// save all thread context in case we need to restore it
if (thread != NULL) thread->set_saved_exception_pc(pc);
uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
// 返回 true 代表 JVM 进程不会退出
return true;
}
VMError err(t, sig, pc, info, ucVoid);
// 生成 hs_err_pid_xxx.log 文件并退出
err.report_and_die();
ShouldNotReachHere();
return true; // Mute compiler
}正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃)
但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事
操作系统如何管理各种I/O
CPU和I/O交互
设备控制器与CPU交互

// 一直等到设备不忙为止
while (STATUS == BUSY);
// Write data to Data register
// 将设备状态设置为忙碌状态
set STATUS register BUSY;
// Write Command to COMMAND register
// 执行命令,执行命令后,将状态设置为就绪态
set STATUS register READY;
这里会有两个问题:
CPU 是怎么知道将数据发送给哪一个设备控制器的寄存器
操作系统为命令、数据、状态寄存器这几个寄存器每个都分配一个端口,通过端口来进行标识
- 端口映射I/O:将每个设备控制器的寄存器标志位不同的端口
- 内存映射I/O:把I/O设备的各个寄存器都编址,看成"内存地址"
CPU 是怎么知道将数据发送到寄存器
通过指令来判断

I/O控制方式
每种设备都有一个设备控制器,控制器相当于一个小 CPU,它可以自己处理一些事情,但有个问题是,当 CPU 给设备发送了一个指令,让设备控制器去读设备的数据,它读完的时候,要怎么通知 CPU 呢?
控制器的寄存器一般会有状态标记位,用来标识输入或输出操作是否完成
- 我们想到第一种轮询等待的方法,让 CPU 一直查寄存器的状态,直到状态标记为完成,很明显,这种方式非常的傻瓜,它会占用 CPU 的全部时间
- 那我们就想到第二种方法 —— 中断(Interrupt),通知操作系统数据已经准备好了。我们一般会有一个硬件的中断控制器,当设备完成任务后触发中断到中断控制器,中断控制器就通知 CPU,一个中断产生了,CPU 需要停下当前手里的事情来处理中断


但中断的方式对于频繁读写数据的磁盘,并不友好,这样 CPU 容易经常被打断,会占用 CPU 大量的时间。对于这一类设备的问题的解决方法是使用 DMA(Direct Memory Access) 功能,它可以使得设备在 CPU 不参与的情况下,能够自行完成把设备 I/O 数据放入到内存

零拷贝
传统数据拷贝过程:
- 用户进程向 CPU 发起一个 read() 的系统调用,用 read() 来读取硬盘上的数据,这时候上下文会从用户态切换为内核态。read() 操作是进程阻塞操作,需要等待数据有返回时才能解除阻塞
- CPU 会对 DMA 控制器发起调度命令,对硬盘发起一个 I/O 请求,把数据读到内核中并缓存起来,之后 DMA 进行拷贝,拷贝到内存缓冲区
- 当拷贝完毕后会 DMA 会发出数据读完信号之后通知 CPU,收到通知后会把内核缓冲区的数据拷贝到用户缓冲区
- 当内核态切换为用户态后会唤醒以及阻塞的用户进程,用户进程就会向 CPU 发起 write() 系统调用,通过 CPU 时间片轮询,用户向读数据必须通过 TCP 网卡设备才能读取数据
- CPU 把用户缓冲区数据拷贝到 Socket 缓冲区,之后由 DMA 发起 I/O 请求,之后由 DMA 拷贝到网卡设备
数据拷贝了 4 次,上下文切换了 4 次
DMA
DMA 就是在主板上面安装了一块独立的芯片,当在内存和 I/O 设备上传输数据的时候,不需要 CPU 来控制数据的传输,而是直接通过 DMA 控制器完成数据传输

MMAP+write 将 PageCahe 数据映射到用户缓存区
- mmap file 使用虚拟内存
- MMAP 减少了一次 CPU 拷贝,还是包括 4 次上下文切换

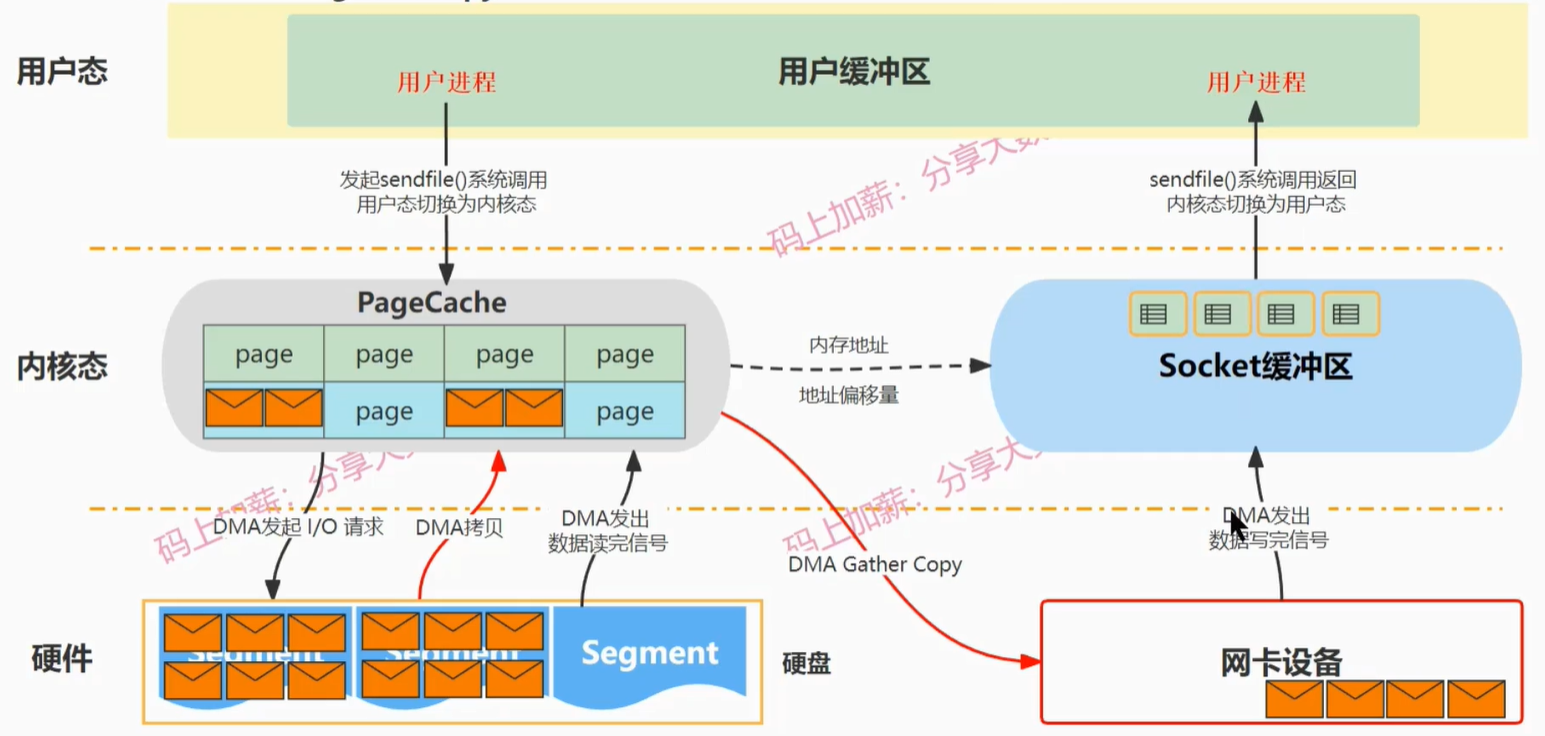
sendfile
sendfile
- 零拷贝是指在用户态没有发生拷贝,而是在内核态发生了一次 CPU 的拷贝

sendfile + DMA gather copy
- 数据拷贝的过程中相当于省去了 CPU 数据拷贝过程,不再需要拷贝到 Socket 缓冲区,通过 DMA Gather Copy 拷贝到网卡设备
splice + DMA copy

I/O
阻塞与非阻塞
BIO(Blocking I/O)
- 你去了书店,告诉老板你想要某本书,然后你就一直在那里等着,直到书店老板找到你想要的书

NIO(Non-Blocking I/O)
NIO:你去了书店,问老板有没有一本书,老板告诉你没有,你就离开了。一周后,你又来了这个书店,再问这个老板,老板一查,有了,于是你买了这本书
问题:每次让应用程序去轮询内核的 I/O 是否准备好,是一个不是很好的做法,因为在轮询的过程中进程啥也不能干(需要占用 CPU)

- 第二种NIO:你去了书店,告诉老板:老板,书到货了给我打电话吧,我再来付钱买书

I/O多路复用
一旦使用 fgets 方法等待标准输入,就没有办法在套接字有数据的时候读出数据,所以需要去掉 write() -> read() 过程

I/O 多路复用:把标准输入、套接字(把用户空间的应用层和内核空间的传输层进行连接)等都看做 I/O 的一路,多路复用的意思,就是在任何一路 I/O 有事件发生的情况下,通知应用程序去处理相应的 I/O 事件
- I/O 事件一:fd 对应的内核缓冲区来了数据,可读
- I/O 事件二:fd 对应的内核缓冲区空闲,可写
- I/O 事件三:fd 出现异常
多路复用实现技术:select、poll、epoll

epoll
select
将需要进行 I/O 操作的 socket 添加到 select 中进行监听,然后阻塞线程,等待操作完成或超时之后,select 系统被激活调用返回,线程再发起 I/O 操作
具体方式还是通过轮询检查所有的 socket,因为单个进程支持的最大文件描述符是 1024,所以实际并发量低于这个数

优缺点:
- 优点:同个线程能执行多个 I/O,跨平台支持
- 缺点:原理上还是属于阻塞,单个 I/O 的处理时间甚至高过阻塞 I/O,需要轮询并发量受限(1024)
poll
同 select 机制类似,但是 poll 基于链表实现,并发量没有限制
优缺点:
- 优点:同个线程能执行多个 I/O,并发量没有限制
- 缺点:依然是遍历链表检查,效率低下
select/poll的缺点
每次调用 select/poll 时都需要在用户态/内核态之间拷贝数据
将应用进程关心的 fd 维护在内核中(支持高效的增删改) -> 红黑树
在内核中,select/poll 在检测 IO 事件时,只要有一个 fd 有事情发生,就会线性扫描所有的 fds,事件复杂度 O(n)
epoll
针对前两者的缺点进行改进,通过 callback 回调通知机制。减少内存开销,不因并发量大而降低效率,linux 下最高效率的 I/O 事件机制
优点: 同个线程能执行多个 I/O,并发量远远超过 1024 且不影响性能 缺点: 并发量少的情况下效率可能不如前两者